Pythonでスクレイピングして情報を取得するのが一番簡単?パート2

みなさん、こんにちは。
クリスマス、やっていたのは原稿作成。PQTomです。
みなさん、今年のクリスマス、どのように過ごしたでしょうか。
恋人とデートした人、家族で団欒した人、ジムで筋トレをしていた人、いろんな人がいると思います。
私は、学校で学会原稿を書き、ブログを書き、筋トレをして、クリスマスワインを飲みながらクリスマスの映画を見ていました。
最高に充実したクリスマスでしたね。。。はい泣。
さて、クリスマスも終わったところで、2018年も残り5日となりました。
気を抜かずもう少し頑張っていきましょう!
今回のお話は、前に話したウェブスクレイピングのお話です。
こちらが前回の記事です。
前回の概要を少し話すと、同じディレクトリにあるhtmlファイルの情報をスクレイピングするっていう内容でした。
本当に基礎の話をして、スクレイピングとはどのようなものなのかの話をしていたら、結局ウェブスクレイピングまではできませんでした。
今回はその続きで、ウェブスクレイピングを行っていこうと思います。
では、行こう。
目次
ウェブスクレイピング
実行環境
実行環境は前回と変わりありません。
・macOS Mojave
・Python 3.6.1
・Anaconda 4.4.0
ウェブサイト
今回、情報をしてくるサイトは
https://pqtomblog.com/pqtom.html
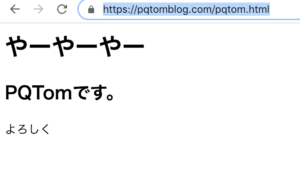
こちらですね。
内容は前回のものと変わりません。
しかし、今回は、自分のパソコンの同じディレクトリ内のファイルではなく、ウェブ上に公開されているデータです。
なので、ウェブスクレイピングとなりますね。
Pythonファイル
では、プログラムを書いていきます。
Beautiful Soup
前回同様、スクレイピングには
Beautiful Soup
というフレームワークを使用します。
まず、このフレームワークの取り込みですね。
from bs4 import BeautifulSoupおっけーい。
Beautiful Soupのインストールの仕方がわからない人は前回の記事を参考にインストールから始めてください。
urllib.request
ウェブスクレイピングを行うために、どのURLから取得するのか指定する必要があります。
pythonではURLの判別をするためのモジュールが存在しており、それが、
urllib.request
です。
urllibパッケージを使ってインターネット上のリソースを取得するには
https://docs.python.jp/3/howto/urllib2.html
詳しくはこれを参考にしてみてください。
では、これを使用していきます。
このモジュールのインポートですね。
import urllib.request as req完了です。
私はいちいちコード上で
urllib.request
と打つのがめんどくさいので、ここでこれから
urllib.requestの代わりにreqで使用できるように設定をしました。
それが
as reqの部分です。ここは自分のわかりやすいものがいいですね。(別に as pqtom でも問題は無いですよ。極論)
URLの指定
どこのurlから情報を取得するのか指定します。
url = "https://pqtomblog.com/pqtom.html"上記にあるように
https://pqtomblog.com/pqtom.html
からの情報取得なのでこうなります。
URLの情報を開く
指定したURLを開きます。
ここで先ほどインポートしたモジュールが役に立つんですよ。
res = req.urlopen(url)urlopenで指定したURLを開きます。そのまんま笑
情報の読み取り
まだURLを開いただけなので、肝心のサイトの情報は読み取れていません。
読み取りましょう。
data = res.read()読み込みはread()です。
では、ここまでの結果を表示してみます。
すると、

あれ、ちょっと何言ってるかわからない笑
この状況だと、本当に機会がこのサイトの情報をそのまま読み取った感じで終わっていますね。
そこで前回使用したBeautiful Soupが役にたちます。
構文解析
Bueautiful Soupを使用して整理します。
soup = BeautifulSoup(data, "html.parser")今回もhtmlパーサを使用します。
この結果、

綺麗になりましたね。
ここまでくればあとは前回同様、タグを指定して、使用したい情報のみを取得していけばおっけーです。
全文
今回の全文載せておきます。参考に。
from bs4 import BeautifulSoup
import urllib.request as req
# URLの設定
url = "https://pqtomblog.com/pqtom.html"
# サイトオープン
res = req.urlopen(url)
# 情報読み取り
data = res.read()
# 整理
soup = BeautifulSoup(data, "html.parser")
print(soup)
まとめ
今回、pythonでウェブスクレイピングを行いました。
長々書いてますが、プログラムを見返すと、全然コードを書くことなく情報が取得できたことがわかるかと思います。
本当に簡単にできるので、試してみるのが良いかと。
やってみるって大事だなっと思う今日この頃です。
ではこのへんで。
でわでわ。