Pythonでスクレイピングして情報を取得するのが一番簡単?

みなさん、こんにちは。
リアルな爬虫類の写真が怖すぎて、やさしめな蛇の写真がないかな〜っと思ってたどり着いたのがこの上の画像です。PQTomです。
爬虫類って怖くないですか?
蛇の画像を探し回っていろいろ見てきたのですが、久しぶりに見たこともあってなんかゾクってしました。
爬虫類好きの人、申し訳ない。
さー気をとりなおして。
みなさん、ウェブスクレイピング(Web scraping)って知っていますか?
簡単に言うと、ウェブ上から情報を取得してくる技術のことです。
今回は、このウェブスクレイピングを実践していきたいと思います。
目次
ウェブスクレイピング
どんな時に使用する?
まずウェブスクレイピングってどんな時に有効活用できるのか。
用途は思いつくだけでたくさんあるのですが、
大量の情報を収集し、そのデータを分析したり(機械学習やDeep learningの材料に使う)、
必要な時に必要な情報のみを抽出したり
って時に有効活用できますね。(その他、多くの場合で有効活用できますね)
実装
とは言っても、ウェブスクレイピングでどのような情報がどのように収集できて、どのように活用できるのかは、
実際に活用してみないとイメージしづらいですよね。
では、やっていきましょう。
実行環境
今回の実行環境は
・macOS Mojave
・Python 3.6.1
・Anaconda 4.4.0
です。
Beautiful Soup
今回のウェブスクレイピングでは
PythonライブラリのBeautiful Soup
を使用します。
日本語のBeautiful Soupのページ
http://kondou.com/BS4/
英語版のページ
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
詳しくはこのライブラリ公式ページを参照していただけるとよいです。
簡単にこのライブラリの説明をすると
いろんなファイルから必要なデータを簡単に収集するため
のものです。
pipインストール
Beautiful Soupを使用するにはまず、このライブラリのインストールが必要ですね。
公式ページにもいろいろ書いてありますが、今回は
pip
を使用してインストールします。
Python Japan
https://www.python.jp/install/ubuntu/pip.html
PyPA pip 18.1
https://pip.pypa.io/en/stable/installing/#installing-with-get-pip-py
pipについてはこれらページなどなどたくさんありますね。
Pythonパッケージをインストールした時点で、pipが使用可能となる場合もあるため、もしできなかったらページを参照してpipをインストールしてくださいね。
pipが使用可能となったら、
$pip install beautifulsoup4これでBeautiful Soupライブラリのインストールが完了します。
HTMLファイル
では、Python、Beautiful Soupを使用してスクレイピングをしていきます。
今回、本当に理解しやすいように、簡単なHTMLを使用します。
<html>
<body>
<h1>やーやーやー</h1>
<h2>PQTomです。</h2>
<p>よろしく</p>
</body>
</html>このようなHTMLがあったとして、おこなっていきます。
スクレイピングにはそのページがどのようなソースコードをしているか理解する必要があります。
Pythonファイル
ライブラリの取り込み
まず、Beautiful Soupライブラリの取り込みます。
from bs4 import BeautifulSoup次に収集したいページのURL、ファイル名を設定します。
html = "pqtom.html"ここでBeautiful Soupを使用します。
soup = BeautifulSoup(html, "html.parser")Beautiful Soupはファイルを指定して、パーサーを指定します。
パーサーとは
構文解析器でそのファイルがどのように書かれているかを解析してくれるいいやつ
です。
html.parserは標準で搭載されているものです。
この他にそれぞれのファイルの形に合わせたパーサーが用意されているので用途に合わせて使い分けてみては。
ここからは取得したい部分を指定して取得していきます。
たとえば、h1の部分を取得したければ、
h1 = soup.html.body.h1となります。
html->body->h1
と順序よく指定していけばいいだけです。
その他の部分も
h2 = soup.html.body.h2
p = soup.html.body.pで取得可能です。
取得したら表示します。
print("h1 = " + h1.string)
print("h2 = " + h2.string)
print("p = " + p.string)
無難にprintを使用して。
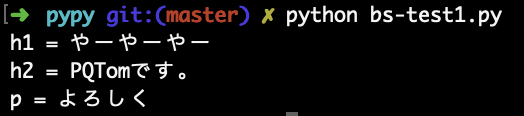
実行
実行結果がこちらです。
全コード
最終的な全コード、bs-test1.pyを出しときます。参考に。
#beautifulsoupの基本的な使い方
#ライブラリを取り込む
from bs4 import BeautifulSoup
#解析したいhtml
html = "pqtom.html"
#htmlを解析する
soup = BeautifulSoup(html, "html.parser")
#任意の部分を抽出する
h1 = soup.html.body.h1
h2 = soup.html.body.h2
p = soup.html.body.p
#要素のテキストを表示する
print("h1 = " + h1.string)
print("h2 = " + h2.string)
print("p = " + p.string)まとめ
今回、htmlファイルをpython、beautiful Soupを使用して取得しました。
初期の初期について話したので、ウェブの情報を取得する部分まではいけませんでした。(申し訳ないです)
次回は、これを元にウェブに公開されている情報を取得する部分について話します。
少々お待ちください。
なぜ、Pythonでスクレイピングをしたのか。
それは
コードが簡単
だからですね。
実質、3行でデータが取得できてるわけなんで。
とりあえずは、Pythonで、これからPHPでの取得についても書いて比較していきたいですね。
では今日はこの辺で。
でわでわ。